Breaking the black box: an interpretable machine learning model for global terrorism forecasting
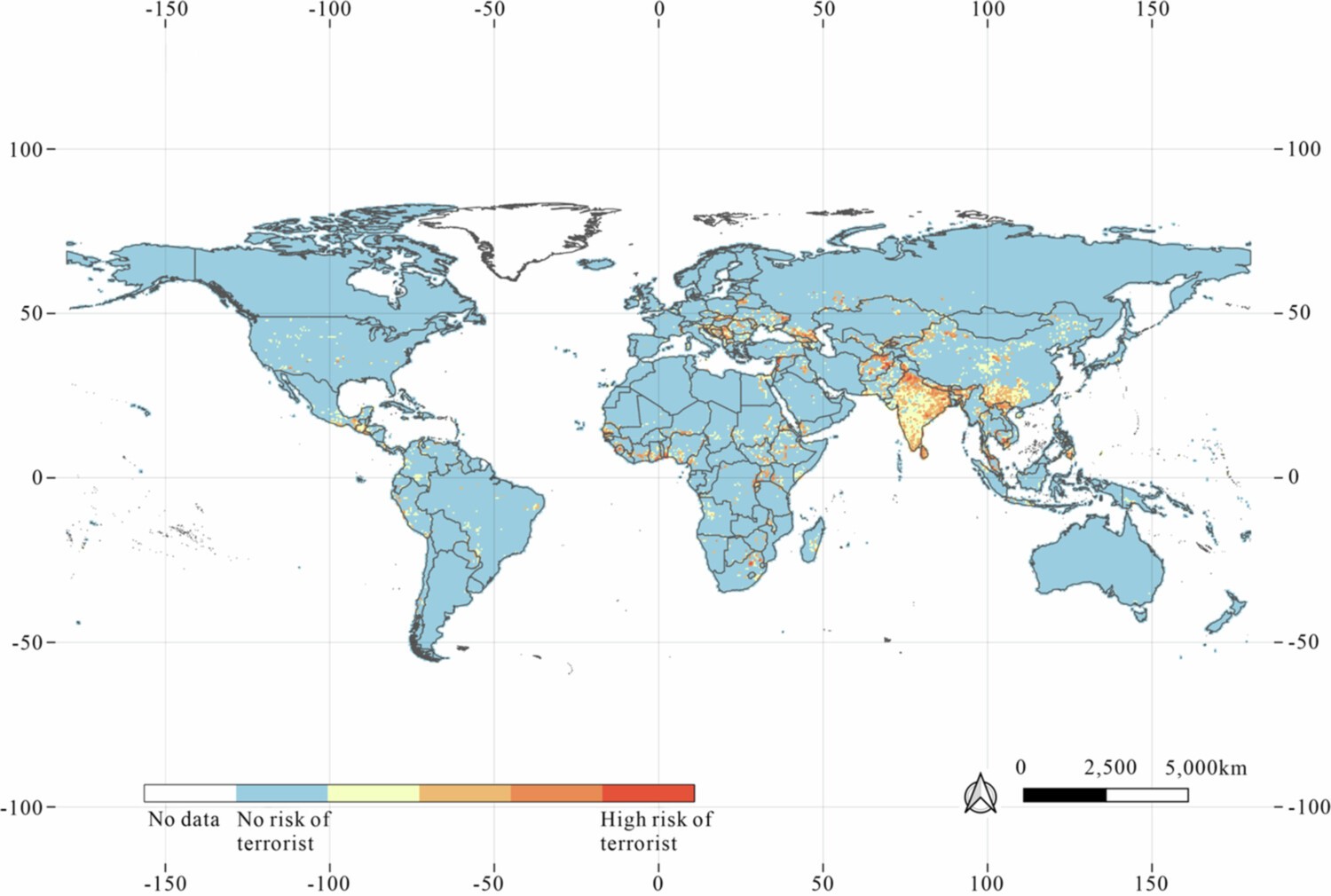
Terrorist attacks significantly threaten a nation’s stability, prosperity, and social cohesion. Therefore, predicting terrorist attacks and identifying their underlying drivers are crucial for formulating effective counterterrorism strategies. Existing studies often prioritize either temporal or spatial dimensions, while their interplay and specific socioeconomic drivers are less explored. In this study, global news data are leveraged to construct a novel global conflict index (GCI), which integrates multisource datasets to comprehensively characterize the key drivers of terrorist attacks. TerrorXG is proposed to predict terrorist attacks, and SHAP analysis is applied to quantitatively interpret the importance and contributions of the driving factors. TerrorXG demonstrated superior performance (RMSE: 0.319; PCC: 0.777) and high computational efficiency. Compared with the second most influential factor (population size), the proposed GCI has a 42.4% greater impact on terrorist attacks. The interpretability analysis of the model highlights socioeconomic inequality as a primary determinant: the impacts of child malnutrition and infant mortality are 38.4% to 108.5% greater than the effect of urbanization. The influence of ethnicity represents only 9.7% of the impact of the GCI, providing empirical evidence that challenges traditional theoretical perspectives on ethnic conflict in terrorism research. This study provides valuable insights for optimizing the allocation of counterterrorism resources.