






基于“人机对抗生成照片-感知数据集”(可参考文章),我们采用武汉地区的街景打分数据训练了六种感知(美观、无聊、压抑、活力、安全和富裕)的深度网络模型,免费提供给各位老师和同学们用于科学研究。
感谢中国地质大学(武汉)地理与信息工程学院2017级软件工程系的王宇同学分享。
相关参考文献和下载地址请见本文末尾。
DCNN网络结构介绍
在本神经网络模型中,我们定义了一个三层双卷积神经网络,输出维度分别是64、64、128、128、和256、256。在最后的输出层定义了一个全连接神经网络,输出维度是1。在定义卷积神经网络过程中,按照一个卷积神经网络的标准结构进行定义,使用最大池化(maxpooling)策略进行降维特征提取,使用Dropout防止过拟合,使用BatchNormalization对隐藏层的输出进行归一化。
以下是一个双卷积神经网络的详细定义过程。
在搭建网络之前,使用tf.keras.Sequential实例化一个model,然后逐层进行网络结构的搭建。
首先,使用双层卷积结构的方式提取图像特征。在第一个卷积网络结构中,输入数据维度是[300,480,3],输出数据维度是64,使用3*3的卷积核,全局使用he_normal进行kernel_initializer,卷积核在X、Y两个方向的移动步幅为1,图像边界处理策略为same,使用relu激活函数。第二个卷积网络去掉input_shape,将上一层网络的输出作为本层的输入,其余参数不变。
第三层添加一个BatchNormalization对上一层的输出数据进行归一化。
第四层添加一个二维池化层,使用最大值池化策略,池化维度为22,即将22局域的像素使用一个最大值代替,步幅为2,padding使用valid策略。
第五层添加一个Dropout层,按照一定的概率随机使神经网络的神经元失效,降低连接的复杂度,防止过拟合,并加快训练速度。
最后添加一个BatchNormalization对输出数据进行归一化。
第二个双卷积网络结构,输出维度设置为128;第三个双卷积网络结构,输出维度设置为256。其余参数不变。
在经过卷积和池化完成特征提取之后,紧接着就是全连接的深度神经网络的输出层。在将数据输入全连接神经网络之前主要进行数据的Flatten操作,将之前的长、宽像素值三个维度的数据压平成一个维度,目的是减少参数的数量。因此,在卷积层和全连接神经网络之间添加一个Flatten层。
最后一层全连接神经网络作为输出层,输出数据维度是1。
网络使用rms_prop作为优化器,损失函数设置为均方误差(mse),模型评价标准为平均绝对误差(mae)。

训练过程
为了增加模型的鲁棒性和泛化性能,我们将原图像进行了尺度变换。将原图通过OpenCV或PIL进行缩放,然后再恢复成原来尺寸,这样我们可以得到一份新的数据样本,同时也增加了训练后模型对不同分辨率图像的适应性。
使用pickle将训练数据、测试数据,及其对应的Label进行打包,方便数据的移动和加载。
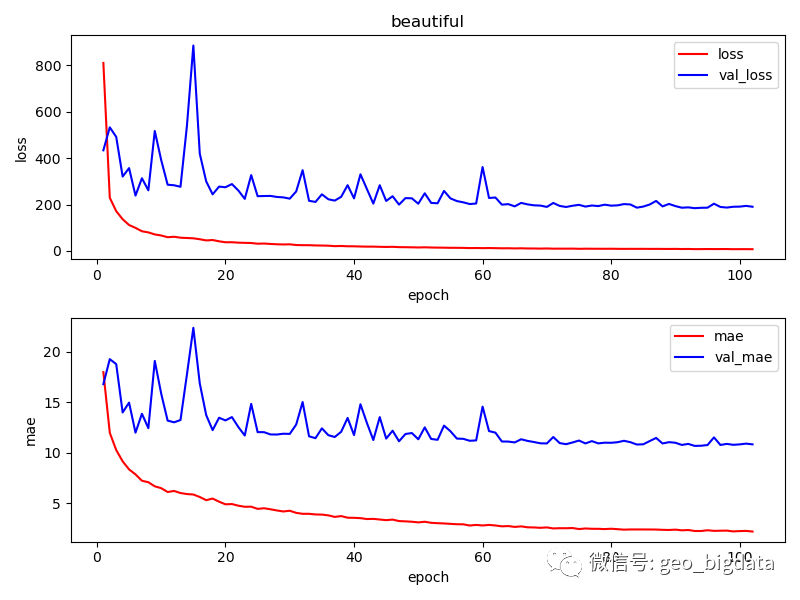
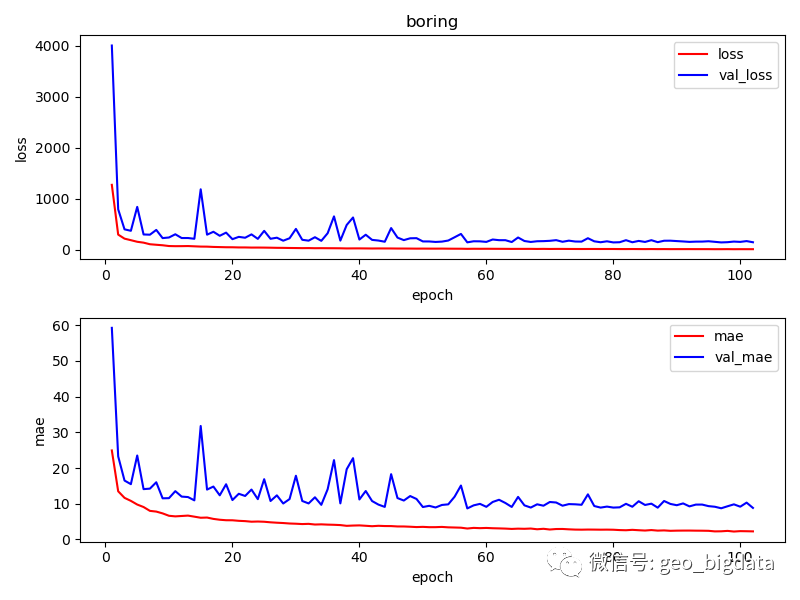
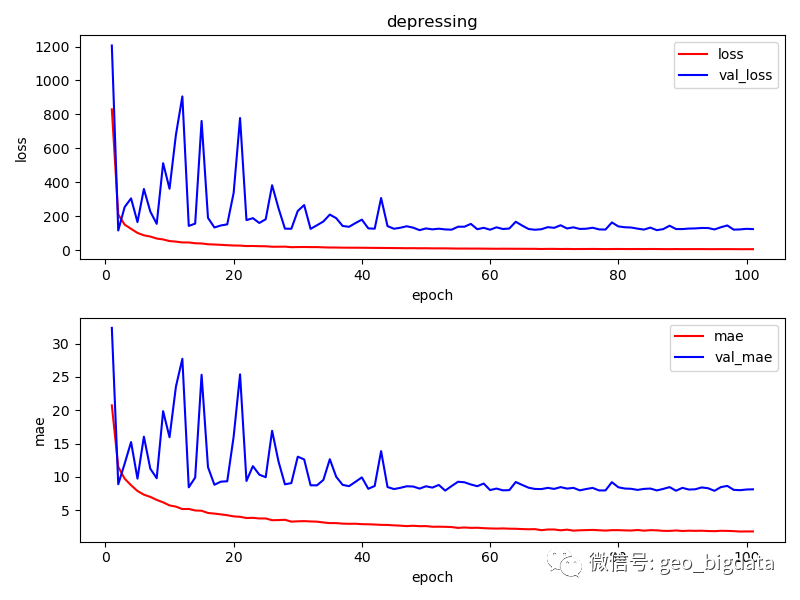
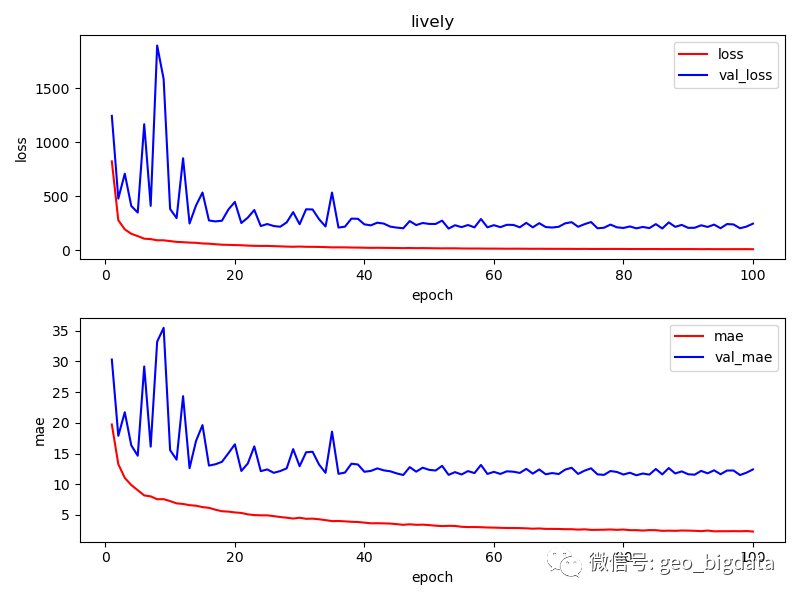
模型精度
对于六个不同的类别,模型最终训练的结果如下图所示。结果仅供参考。其中,每一种感知分数范围是0-100分,0表示最低,100表示最高。
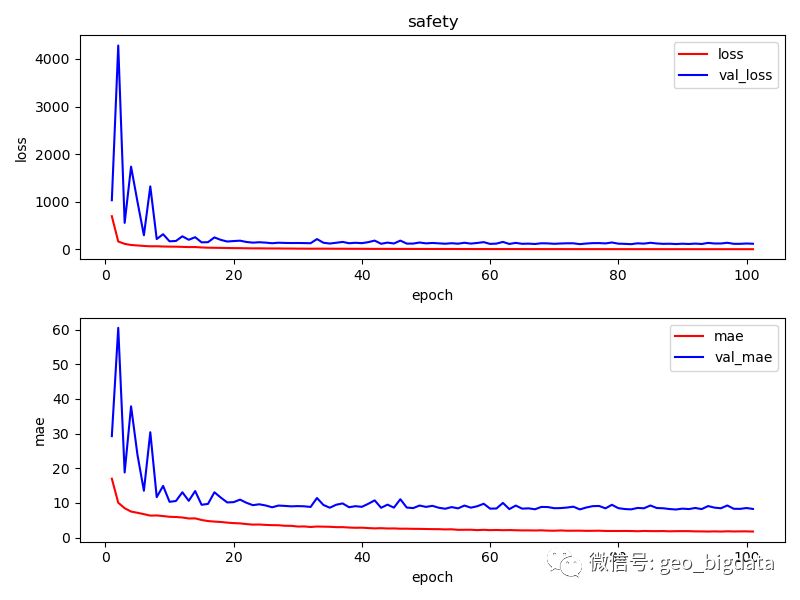
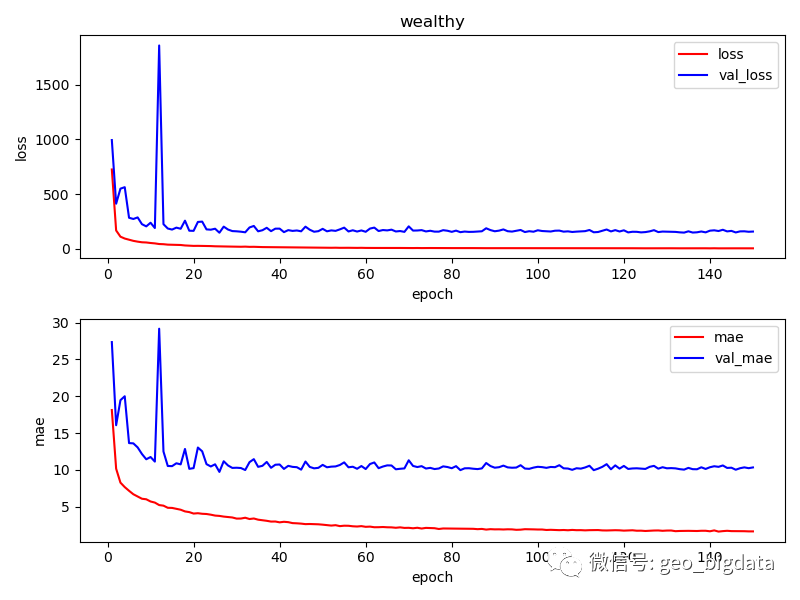
预训练模型下载地址
下载地址:
https://github.com/whuyao/Urban_Perception_CNN_Model
./predict_model.py 示例python代码
./model_dir 模型集和精度表
参考文献:
- Yao Y, Liang Z, Yuan Z, et al. A human-machine adversarial scoring framework for urban perception assessment using street-view images[J]. International Journal of Geographical Information Science, 2019, 33(12): 2363-2384. (Inside Website)
- Wang, R., Ren, S., Zhang, J., Yao, Y., Wang, Y., & Guan, Q. (2021). A comparison of two deep-learning-based urban perception models: which one is better?. Computational Urban Science, 1(1), 1-13.(Inside Website)
Q.E.D.